Pada Machine Learning #2 MESIN belajar (training) untuk menyelesaikan persamaan linear, sekarang selanjutnya training untuk persamaan non linear. Kita contohkan menggunaan persamaan sinusoida.
Mari gunakan persamaan sederhana y = sin(x).
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import math
from tensorflow.keras import layers
# Membuat 1000 nilai random berdasarkan seed 1234, silahkan diganti untuk pola random lain
nsamples=1000
np.random.seed(1234)
x_values = np.random.uniform(low=0, high=(2 * math.pi), size=nsamples)
# masing masing nilai dibuat dalam bentuk sinusoida
y_values = np.sin(x_values) + (0.1 * np.random.randn(x_values.shape[0]))
plt.plot(x_values, y_values, '.')

# membagi menjadi 3 kategori data, untuk validasi, untuk test dan untuk training
val_ratio = 0.2 # 20% untuk data validasi
test_ratio = 0.2 # 20% untuk data test, dan sisanya untuk data training
val_split = int(val_ratio * nsamples)
test_split = int(val_split + (test_ratio * nsamples))
x_val, x_test, x_train = np.split(x_values, [val_split, test_split])
y_val, y_test, y_train = np.split(y_values, [val_split, test_split])
# Cek hasil split apakah benar, jika salah maka munculkan assertment
assert(x_train.size + x_val.size + x_test.size) == nsamples
# TAmpilkan data dengan warna yang berbeda:
plt.plot(x_train, y_train, 'b.', label="Data u/ Train")
plt.plot(x_test, y_test, 'r.', label="Data u/ Test")
plt.plot(x_val, y_val, 'y.', label="Data u/ Validasi")
plt.legend()
plt.show()

# Membuat model dengan 2 layer
model = tf.keras.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(1,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1))
# Lihat pemodelan
model.summary()
Kode diatas adalah untuk membuat model 2 layer yang sekuensial. Layer pertama 16 neuron dengan 1 input. Layer kedua dengan 16 neuron, dan outpunya 1 neuron untuk 1 output. jenis aktivasinya adalah ReLU atau Rectified Linear Unit

# Gunakan optimizer RMSprop , loss function Mean absolute error
model.compile(optimizer='rmsprop', loss='mae', metrics=['mae'])
# Training model
history = model.fit(x_train, y_train, epochs=500, batch_size=100,
validation_data=(x_val, y_val))
Untuk kali ini, menggunakan RMSProp sebagai optimizer. Pada training untuk persamaan linear Machine Learning #1, yang digunakan adalah SGD (Stochastic Gradient Descent). Pada training ini SGD terlalu lambat dan bisa jadi tidak bisa menemukan nilai minimum lost terendah. Perhatikan perbandingan berikut, SGD ditunjukkan dot warna merah:
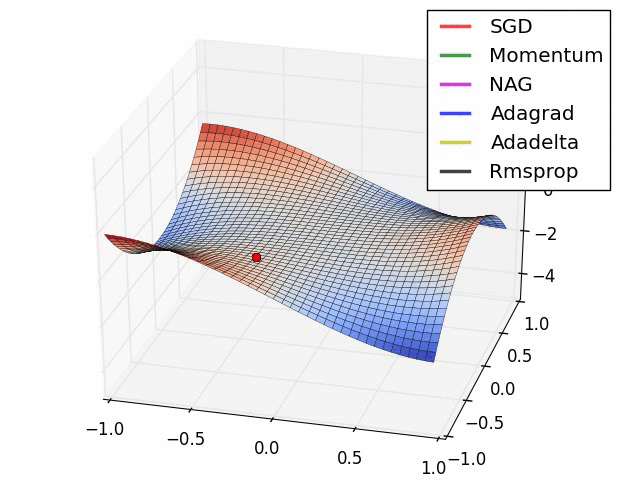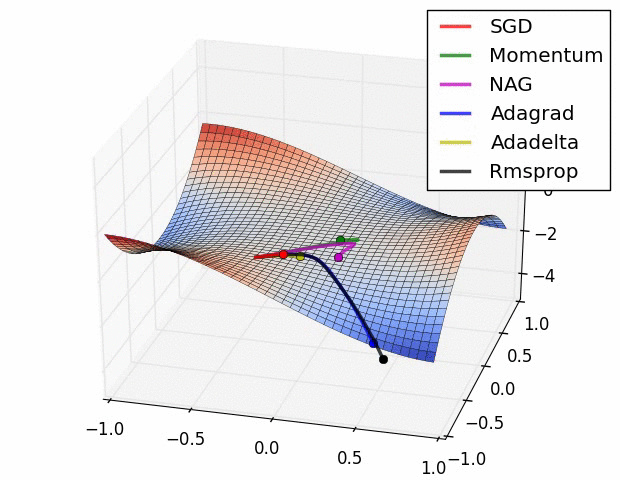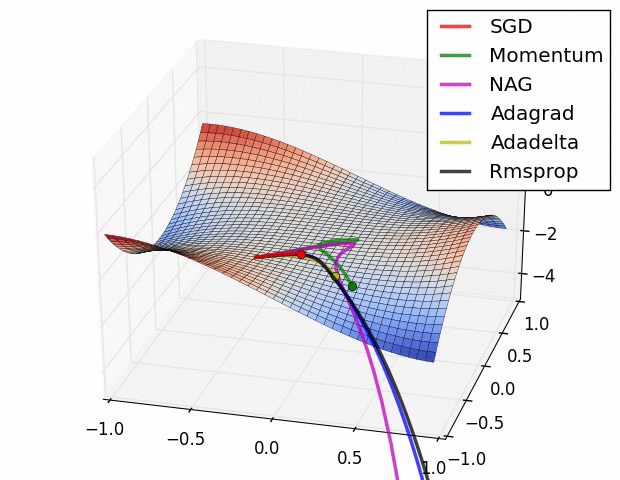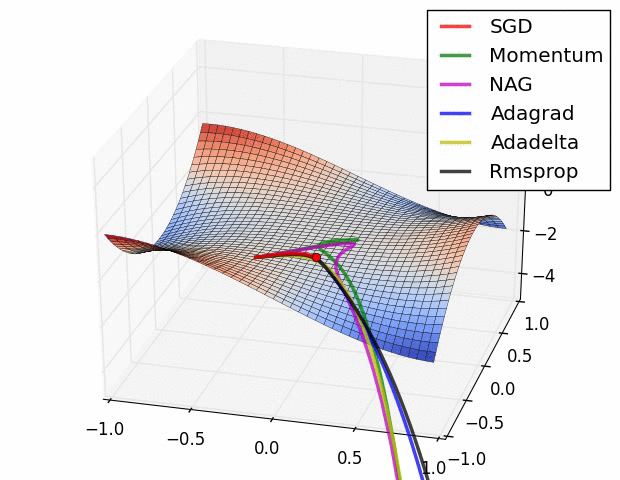
Sedangkan untuk mencari nilai loss, yang digunakan adalah MAE (Mean absolute error) dimana selisih erornya di absolutekan jadi nilai positif semua. Berbeda dengan yang sebelumnya, dimana menggunakan MSE (Mean Squared Error) yang mengakarkan total nilai error.

Pada baris ke 47, MESIN diberikan 500 epoch untuk proses training, berdasarkan data training (x_train, y_train) dan kemudian mengevaluasi dengan data evaluasi (x_val, y_val). Ukuran batch yang digunakan adalah 100.
Jika ukuran tumpukan batch kecil, misalnya 1, maka gradien hanya dihitung dengan satu contoh pelatihan. Hal ini dapat membuat kerugian pelatihan yang berosilasi, karena setiap kali memperkirakan gradien hanya dengan satu contoh pelatihan, yang sering kali tidak mewakili seluruh data pelatihan. Jadi, semakin banyak contoh pelatihan yang digunakan, semakin baik dalam memperkirakan gradien (yang akan sesuai dengan semua contoh pelatihan), sehingga ini berpotensi mengarah pada konvergensi yang lebih cepat. Namun, jika menggunakan banyak contoh pelatihan, biayanya juga bisa mahal secara komputasi. Misalnya, bayangkan data pelatihan terdiri dari jutaan contoh pelatihan. Dalam hal ini, untuk melakukan satu langkah penurunan gradien, harus melalui semua pelatihan yang dapat memakan banyak waktu.

Jika ingin melihat history loss dari hasil training, dapat gunakan skrip berikut:
# Plot hasil training, jika tidak diperlukan kode ini bisa diabaikan
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
Selanjutnya mari buat perbandingan hasil training berdasarkan dengan model matematikan sebenarnya (y=sin(x))
# Plot hasil prediksi terhadap nilai sebenarnya yaitu y = sin(x)
predictions = model.predict(x_test)
plt.clf()
plt.title("Perbandingan hasil training berdasarkan dengan model matematikan sebenarnya")
plt.plot(x_test, y_test, 'b.', label='Nilai Test')
plt.plot(x_test, predictions, 'r.', label='Nilai Prediksi')
plt.legend()
plt.show()

Warna biru adalah nilai data test hasil sinus yang sudah diberi noise. Warna merah adalah prediksi MESIN. Walaupun data training sudah ditambahkan noise (Baris 12), mesin dapat mesin dapat memprediksi bahwa data training adalah persamanan sinus.